

The emergence of cloud native architectures and the use of AI/ML over federated data sources brings benefits in terms of efficiency and adaptability compared to legacy data architectures. However, challenges arise in terms of privacy and security for the data, the distributed infrastructure and the virtualised services and applications. To address these challenges, PAROMA-MED project delivers an open-source platform to deal with privacy preservation in scalable and reliable way that will be catering for the establishment of personal data federation practices.
In the current era, data emerge as a highly value commodity and the need for insightful knowledge relies on the availability of large volumes of data. However, privacy concerns, fueled by the increasing awareness about the fundamental digital rights of the individuals, and continuously evolving data regulations, especially in EU, pose certain obstacles that make traditional methods of data aggregation and analysis obsolete.
The data availability we have experienced so far was established during the last decades through user interaction with online services and platforms because of their voluntary (or neglectful) behavior to create content. This has fueled the production of the Large Language Models that have radically changed the current service and application landscape but at the same time they have triggered discussions about the created value and the potentially neglected royalties that may be stemming from training data ownership but equally important about privacy violation.
The need, however, for continuous evolution of AI, in view of its countless capabilities, requires that such obstacles are properly removed but also that the rights of individuals are protected adequately. Federated Learning emerges as a radical solution, establishing a path forward by ensuring data privacy while allowing machine learning models to evolve.
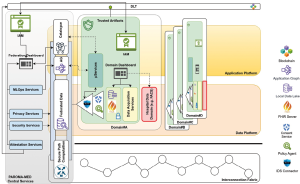
Figure 1: Hybrid Cloud Architecture
The Concept of Federated Learning
Federated Learning is based on a distribution approach regarding execution of the learning cycles and tasks, introducing a completely new fundamental approach in machine learning workflows. In contrast to current methods that require transfer and centralization of data for performing analysis and training computations, Federated Learning distributes the learning tasks to the computing resources at the border of the privacy perimeter of domains, networks or even personal equipment. In this way, devices, such as edge nodes, gateways, smartphones or Internet of Things (IoT) devices, take over computations on local data sets and update a global model in collaboration with other peer nodes participating in the training.
This edge empowered approach, which can also aid in real-time insights and adaptive decision-making without cloud infrastructure dependencies especially in the context of Data Spaces, eliminates the need for data movements thus contributing to better user privacy protection as well as to better controlled and managed access to data resources. From ML point of view, the model is the only part that is centralised and evolves through the updates collected by a central entity, from each one of the peripheral nodes, ensuring collective intelligence of the distributed data without the compromising of privacy that is left open when data leave their vault. Additionally, the participation of peripheral nodes (and consequently of the data used for the training) can be fully traceable ensuring, potentially, better handling of data royalties due to the contribution to a model that can be thereafter monetized.
Federated Learning addresses privacy concerns by design and can be further enhanced in terms of privacy effectiveness if combined with cryptographic techniques such as federated averaging and differential privacy that can be used for obfuscating sensitive information. These features make Federated Learning a good candidate for intelligence and insightful knowledge creation in industries like healthcare and finance, where data confidentiality is paramount. For example, medical institutions can collaboratively improve models for diagnostic purposes without direct exposure of patient records.
Challenges and Future Directions
As it happens with all distributed patterns, Federated Learning is challenged by aspects such adequate communication for the entire machine learning workflows (discovery, negotiation, preparation and model training and synchronization) especially when it comes to heterogeneous devices and varied networking conditions. Luckily, in the context of the ongoing Data Space evolution, a new paradigm shift in that field (e.g. PAROMA-MED project) based on the repositioning of the primary objective of data sharing towards distributed use of data through code to data techniques can overcome this challenge by eliminating at the same time obstacles stemming from heterogeneity due to the fact that Data Spaces are already being built on top of well-defined protocols, procedures and identity management procedures.
Furthermore, PAROMA-MED project considers the protection of the produced AI model in the same way as it does with all other data resources. Therefore, AI/ML researchers are empowered to express the high-level requirements for privacy and security (privacy and security by design) during the training phase of their models so that the platform marketplace backend service can apply automatically the deployment of the Machine Learning Operation (MLOps) artifacts, ensuring enforcement of the security constraints through smart contracts and policy agents, during the training and distribution of the produced models.
 Further information
Further information
- PAROMA-MED project website: https://paroma-med.eu/